MS SQL Server サンプルデータの AdventureWorksDW2019 スキーマを使って T-SQL を覚えるメモ。
ファクトテーブルの dbo.FactInternetSales と関連ディメンションテーブルを結合して、購入金額のデータ分布(ヒストグラム)を抽出する。
with t1 as (
SELECT
s.[ProductKey],
s.[CustomerKey],
d.[FullDateAlternateKey],
convert(varchar(7), format(d.[FullDateAlternateKey], 'yyyy-MM')) as year_month,
s.[SalesOrderNumber],
s.[SalesOrderLineNumber],
s.[OrderQuantity] * s.[UnitPrice] as revenue,
pc.[EnglishProductCategoryName] as category,
psc.[EnglishProductSubcategoryName] as subcategory,
p.[EnglishProductName] as productname
FROM
[dbo].[FactInternetSales] as s
inner join [dbo].[DimDate] as d on s.[OrderDateKey] = d.[DateKey]
inner join [dbo].[DimProduct] as p on s.[ProductKey] = p.[ProductKey]
left join [dbo].[DimProductSubcategory] as psc on p.[ProductSubcategoryKey] = psc.[ProductSubcategoryKey]
left join [dbo].[DimProductCategory] as pc on psc.[ProductCategoryKey] = pc.[ProductCategoryKey]
where
1 = 1
and s.[OrderDate] between '2013-01-01' and '2013-12-31'
),
t2 as (
select
2500.0 as revenue_max,
0.0 as revenue_min,
2500.0 as revenue_range,
5 as buckets
),
t3 as (
select
t1.[revenue],
t2.[revenue_min],
t1.[revenue] - t2.[revenue_min] as revenu_diff,
1.0 * t2.[revenue_range] / t2.[buckets] as bucket_range,
floor(
1.0 * (t1.[revenue] - t2.[revenue_min]) / (1.0 * t2.[revenue_range] / t2.[buckets])
) + 1 as bucket
from
t1,
t2
)
select
t3.[bucket],
t3.[revenue_min] + t3.[bucket_range] * (t3.[bucket] - 1) as lower_limit,
t3.[revenue_min] + t3.[bucket_range] * t3.[bucket] as upper_limit,
count(t3.[revenue]) as order_cnt,
sum(t3.[revenue]) as total_revenue
from
t3
group by
t3.[bucket],
t3.[revenue_min],
t3.[bucket_range]
order by
t3.[bucket];
結果はこうなる。
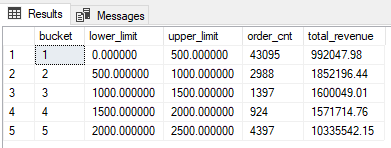
T-SQL でデータ分布を抽出
PowerBI で表示するとこうなる。
X 軸の「内側のパディング」は 0 px にしてます。
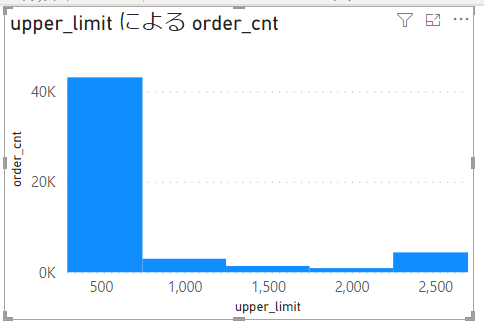
PowerBI でデータ分布(ヒストグラム)を表示
参考図書
ビッグデータ分析・活用のためのSQLレシピ
SQL Server 2016の教科書 開発編